※ (링크) 바킹독 유튜브 영상을 통해
학습한 내용을 정리한 것입니다.
본인은 JAVA를 활용해 학습하였습니다
비상업적 목적이며, 개인 복습을 위해 업로드한 글임을 다시 한 번 더 이야기드립니다.
본문의 모든 내용의 출처는 아래 명시된 링크와 같습니다.
[목차] 알고리즘 설명, 예시, BFS vs DFS
[실전 알고리즘] 0x0A강 - DFS
드디어 01 02 03 이렇게 숫자를 넘어서 0A강에 도달했습니다. 아직 완결까지는 한참 남았지만 아무튼 힘을 내서 계속 잘 해봅시다. 아, 참고로 저번 단원보다는 내용이 많지 않아
blog.encrypted.gg
출처: blog.encrypted.gg/942?category=773649
알고리즘 설명
DFS( Depth First Search )는 다차원 배열에서 각 칸을 방문할 때, 깊이를 우선으로 방문하는 알고리즘입니다. BFS는 깊이 대신 너비를 우선으로 방문한다는 점에서 차이가 있습니다.
예시
BFS와 구현에서의 차이는 BFS는 Queue를 사용했다면, DFS는 Stack을 사용해 구현됩니다. 과정을 한 번 보겠습니다.
- 시작하는 칸을 스택에 넣어 방문한 표시를 남깁니다.
- 스택에서 원소를 꺼내 그 칸과 상하좌우로 인접한 칸에 대해 (3)번을 진행합니다.
- 해당 칸을 이전에 방문했다면 아무 것도 하지 않고, 처음으로 방문했다면 방문 표시를 남기고 해당 칸을 스택에 삽입합니다.
- 스택이 빌 때까지 (2)번을 반복합니다.
모든 칸이 스택에 한 번씩 들어가므로 시간복잡도는 칸이 N개일 때, O(N)입니다.
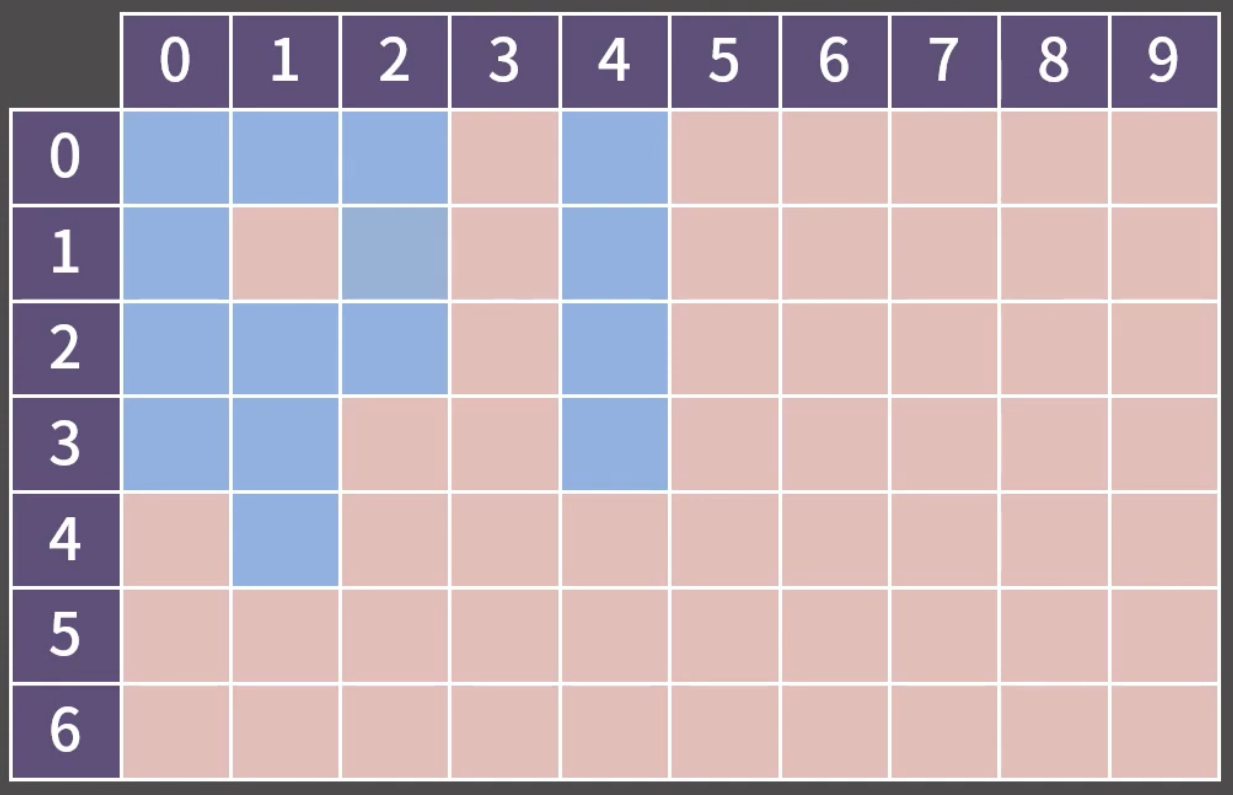
(0, 0)과 상화좌우로 이어진 모든 파란색 칸을 확인해보겠습니다.
우선 (0, 0)에 방문했다는 표시를 남기고, 해당 칸을 스택에 넣습니다. 이 과정은 초기 세팅입니다.
| (0, 0) |
이후에는 스택이 빌 때까지, 스택의 top을 빼고 해당 좌표의 상하좌우를 살피며 스택에 넣는 작업을 반복합니다. 현재 스택의 탑은 (0, 0)이며 Pop을 한 뒤 작업해보겠습니다.
pop 값: (0, 0)
(0, 0)의 상하좌우 칸을 보는데, 파란 칸이며 아직 방문하지 않은 칸을 찾을 것입니다. 보면 (1, 0)과 (0, 1) 모두 조건에 만족합니다. 그렇기에 방문했다는 표시를 남기고 스택에 넣습니다.
| (0, 1) | (1, 0) |
이때 top은 (1, 0)이며, 마찬가지로 pop을 합니다.
pop 값: (1, 0)
상하좌우 칸을 확인해 만족하는 값을 표시를 남기고 스택에 넣습니다.
| (0, 1) | (2, 0) |
해당 과정을 반복합니다.
pop 값: (2, 0)
| (0, 1) | (2, 1) | (3, 0) |
pop 값: (3, 0)
| (0, 1) | (2, 1) | (3, 1) |
pop 값: (3, 1)
| (0, 1) | (2, 1) | (4, 1) |
이때 (2, 1)은 이미 방문 체크가 되어있어 추가로 stack에 삽입되지 않습니다.
pop 값: (4, 1)
| (0, 1) | (2, 1) |
pop 값: (2, 1)
| (0, 1) | (2, 2) |
pop 값: (2, 2)
| (0, 1) | (1, 2) |
pop 값: (1, 2)
| (0, 1) | (0, 2) |
pop 값: (0, 2)
| (0, 1) |
pop 값: (0, 1)
Stack이 비어있으므로 반복을 종료합니다.
DFS도 BFS처럼 Flood Fill이 필요할 때 사용할 수 있습니다.
Flood Fill : 다차원 배열에서 어떤 칸과 연결된 영역을 찾는 알고리즘 입니다.
DFS와 BFS는 최종적인 결과는 같을지라도 방문 순서에서 굉장히 큰 차이가 존재합니다. 우선 DFS의 Default 코드를 살피겠습니다.
BFS의 코드에서 Queue만 Stack으로 바꾼 것입니다. 해당 설명은 BFS 포스팅을 참고해주세요.
BFS vs DFS
위 사실로 확인했을 때, 구현에서의 차이는 BFS는 Queue를 쓰고, DFS는 stack을 쓴다는 차이가 존재한다는 것을 알 수 있습니다. 하지만 원소를 하나를 빼내고 주변을 살핀다는 알고리즘의 흐름은 동일합니다.
그러나 둘의 방문 순서는 큰 차이가 존재합니다.

먼저 BFS는 냇가에 돌이 던져 동심원(파동)이 퍼져나가는 것처럼 상하좌우로 퍼져나갑니다. 이로 알 수 있는 것은 BFS 알고리즘은 거리 순으로 방문한다는 사실이 잘 성립함을 알 수 있습니다.
DFS는 BFS와 달리 한 방향이 막힐 때까지 쭉 직진한다는 사실을 알 수 있습니다. 위 이미지에서 한 눈에 알 수 있듯이 BFS와 DFS는 방문 순서에 큰 차이가 존재합니다.
또 다른 차이는 아래와 같습니다.
- BFS : "대상으로 하는 칸과 인접한 칸과의 거리는 1이다."라는 성질이 성립함
- DFS : "대상으로 하는 칸과 인접한 칸의 거리는 1이다."라는 성질이 성립하지 않음
그렇기에 DFS에서 거리를 계산하는 것이 불가합니다. 다차원 배열에서 BFS 대신 DFS를 사용하는 일은 거의 없습니다. Flood Fill은 BFS와 DFS 중 어떠한 것을 사용해도 상관 없으나, 거리를 측정하는 것은 BFS만 가능하니 거리 측저으이 경우 BFS 대신 DFS를 사용할 일이 없습니다.
그래서 다차원 배열에서 순회하는 문제를 풀 경우 BFS를 사용하게 될 것입니다. 그렇다고 해서 DFS가 아에 무쓸모한 것이 아닙니다. 후에 그래프와 트리구조라는 자료구조를 배울 때, DFS가 사용되게 됩니다.
문제집
github.com/encrypted-def/basic-algo-lecture/blob/master/workbook.md
encrypted-def/basic-algo-lecture
바킹독의 실전 알고리즘 강의 자료. Contribute to encrypted-def/basic-algo-lecture development by creating an account on GitHub.
github.com
'Programming > Algorithm' 카테고리의 다른 글
| [바킹독: 알고리즘] 재귀 (0) | 2021.04.23 |
|---|---|
| [바킹독: 알고리즘] BFS 알고리즘 (너비 우선 탐색) (0) | 2021.04.20 |
| [바킹독: 알고리즘] 스택의 활용(수식의 괄호 쌍) (0) | 2021.04.15 |
| [바킹독: 알고리즘] 덱(Deque) (0) | 2021.04.12 |
| [바킹독: 알고리즘] 큐(Queue) (0) | 2021.04.11 |


