스프링 부트에서 JPA 사용하기 (1)
ORM : Object Relational Mapping JPA를 이해하기전 알고 가야할 것은 ORM이라는 개념입니다. 객체가 테이블이 되도록 매핑 시켜주는 프레임워크 객체와 DB의 테이블 매핑을 이루는 것 자바 객체와 쿼리를
sky-abraxas.tistory.com
프로젝트에 Spring Data JPA 적용하기
1. build.gradle에 의존성 등록

- compile('org.springframework.boot:spring-boot-starter-data-jpa')
- 스프링 부트용 Spring Data JPA 추상화 라이브러리
- 스프링 부트 버전에 맞추어 자동으로 JPA관련 라이브러리들의 버전을 관리함 - compile('com.h2database:h2')
- 인메모리 관계형 데이터베이스
- 자바 기반의 오픈소스 관계형 데이터베이스 관리 시스템
- 별도로 설치를 할 필요 없이 프로젝트 의존성만으로 관리할 수 있음
- 메모리에서 실행되기에 어플리케이션을 재시작할 때마다 초기화되어 테스트 용도로 많이 사용됨
2. 패키지 생성

domain 패키지는 도메인을 담을 패키지입니다. 여기서 의미하는 도메인이란 게시글, 댓글, 회원, 정산, 결제 등 소프트웨어에 대한 요구사항 혹은 문제 영역입니다. 쿼리의 결과를 담는 일들을 도메인 클래스에서 해결하고자 합니다.

Posts 클래스는 DB 테이블과 매칭될 클래스이며, Entity 클래스라고도 합니다. JPA를 사용한다면 실제 쿼리를 작성해 날리기 보다는 Entity 클래스 수정을 통해 작업합니다.
Entity 클래스 : DB 테이블과 매칭될 클래스
- @Entity
- JPA 어노테이션
- 테이블과 링크될 클래스
- 언더스코어 네이밍(_)으로 테이블 이름을 매칭함
ex) SalesManager .java -> sales_manager table - @Getter, @NoArgsConstructor : Lombok 어노테이션
- @Id
- 해당 테이블의 PK(기본키) 필드를 나타냄 - @GeneratedValue
- PK(기본키)의 생성 규칙을 나타냄
- 스프링 부트 2.0에서는 GenerationType.IDENTITY 옵션을 추가해야 auto_increment가 됨 - @Column
- 테이블 컬럼을 나타내며, 선언하지 않아도 해당 클래스의 필드는 모두 컬럼이 됨
- 기본값 외에 추가로 변경이 필요한 옵션이 있을 경우 사용함
- 문자열의 경우 VARCHAR(255)가 기본값인데, 사이즈를 500으로 늘리고 싶거나, 타입을 TEXT로 변경하고 싶을 때 사용됨
참고
- Entity의 기본키(PK)는 Long 타입의 Auto_Increment를 추천함
- 비즈니스상 유니크 키나 여러 키를 조합한 복합키로 기본키(PK)를 잡을 경우 난감한 상황이 발생함
EX. (1) 외래키(FK)를 맺을 떄. 다른 테이블에서 복합키를 전부 갖고 있거나 중간 테이블을 하나 더 둬야하는 상황 발생
(2) 인덱스에 좋은 영향을 끼치지 못함
(3) 유니크한 조건이 변경될 경우 기본키(PK) 전체를 수정해야하는 일 발생
고로 주민등록번호, 복합키 등은 유니크 키로 별도로 추가하는 것 추천
- @NoArgsConstructor
- 기본 생성자를 자동으로 추가함
- 즉, public Posts( ) { }와 같은 효과 - @Getter
- 클래스 내 모든 필드의 Getter 메소드 자동 생성 - @Builder
- 해당 클래스의 빌더 패턴 클래스 생성
- 생성자 상단에 선언할 경우 생성자에 포함된 필드만 빌더에 포함
롬복 어노테이션 사용의 이점은?
구축 단계에서 테이블 설계. 즉, Entity 설계가 빈번하게 변경됩니다. 이때 롬복 어노테이션을 사용해 코드 변경량을 최소화할 수 있습니다.
빌더 패턴이란?
- 디자인 패턴 중 하나로 생성과 표현의 분리
- 어떤 필드에 어떤 인자를 넣어주는지 명확히 알 수 있으며, 굳이 넣어줄 필요 없는 Null 필드는 굳이 선언할 필요 없음
- 각각 객체에 들어갈 인자가 다를 때, 유연하게 사용할 수 있음
- 무조건적인 setter 생성을 방지하고 불변 객체로 만들 수 있음
- 필수 Argument를 지정할 수 있음
빌더 패턴에 대해서는 추가로 상세하게 다루어야할듯 합니다. 우선 정말 간단하게 요약하자면 Setter를 하나의 메서드로 생성했다고 이해하면 좋을듯합니다.
왜 Setter 메소드를 따로 만들지 않았나?
만약 getter/setter 메서드를 무조건 생성한다면, 인스턴스 값이 언제 어디서 변경되어야 하는지 코드상 명확한 구분이 불가합니다. 간단한 코드라면 모르겠지만, 코드가 증가하며 향후 값을 변경해야 하는 일이 생기는 경우 복잡해질 수 있습니다.
그렇기에 Setter 메소드를 생성하지 않고, 필드 값의 변경이 필요하면 명확히 목적과 의도를 나타낼 수 있는 메소드를 추가하는 것이 좋습니다. 아래 예시로 살펴보겠습니다.
- Setter로 제어하는 경우

-- 매개변수로 전달되는 인자 값의 연산을 계산하거나, 해당 인자 값을 확인해야함
- 메서드를 통한 인스턴스 값 변경
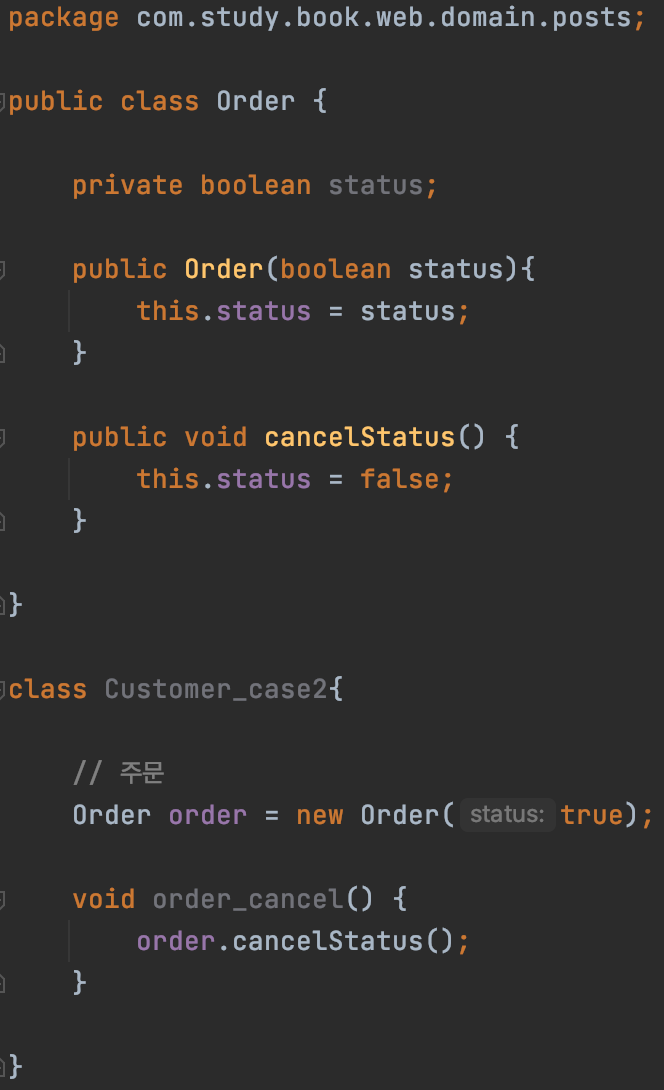
-- 메서드명으로 코드 직관화를 통해 생산성을 높일 수 있음
그렇다면 두 번째 예시에서 Setter 없이 어떻게 값을 채워 DB에 삽입할 수 있는가?
- (가장 기본적인 구조) 생성자를 통해 값을 채운 후 DB에 삽입
- 값 변경이 필요한 경우 해당 이벤트에 맞는 public 메소드를 호출해 변경하는 것을 전제로 함 - 생성자 대신 @Builder를 통해 제공되는 빌더 클래스 사용
- 생성자와 빌더는 생성 시점에 값을 채워준다는 공통점이 있음
- 다만, 생성자는 채워야 하는 필드가 무엇인지 명확히 지정할 수 없음
위 문제에 대한 예시 코드를 보겠습니다. 생성자로 값을 할당할 경우 Human error로 인해 매개변수 인자 값의 순서가 바뀔경우 이를 실행하기 전 혹은 발견하기 전까지 인지하기란 쉽지 않습니다.
아래의 경우처럼 말입니다.

하지만 빌더를 사용한다면, 어느 필드에 어떤 값을 채워야 할지 명확하게 인지할 수 있어 이와 같은 문제를 방지할 수 있습니다.
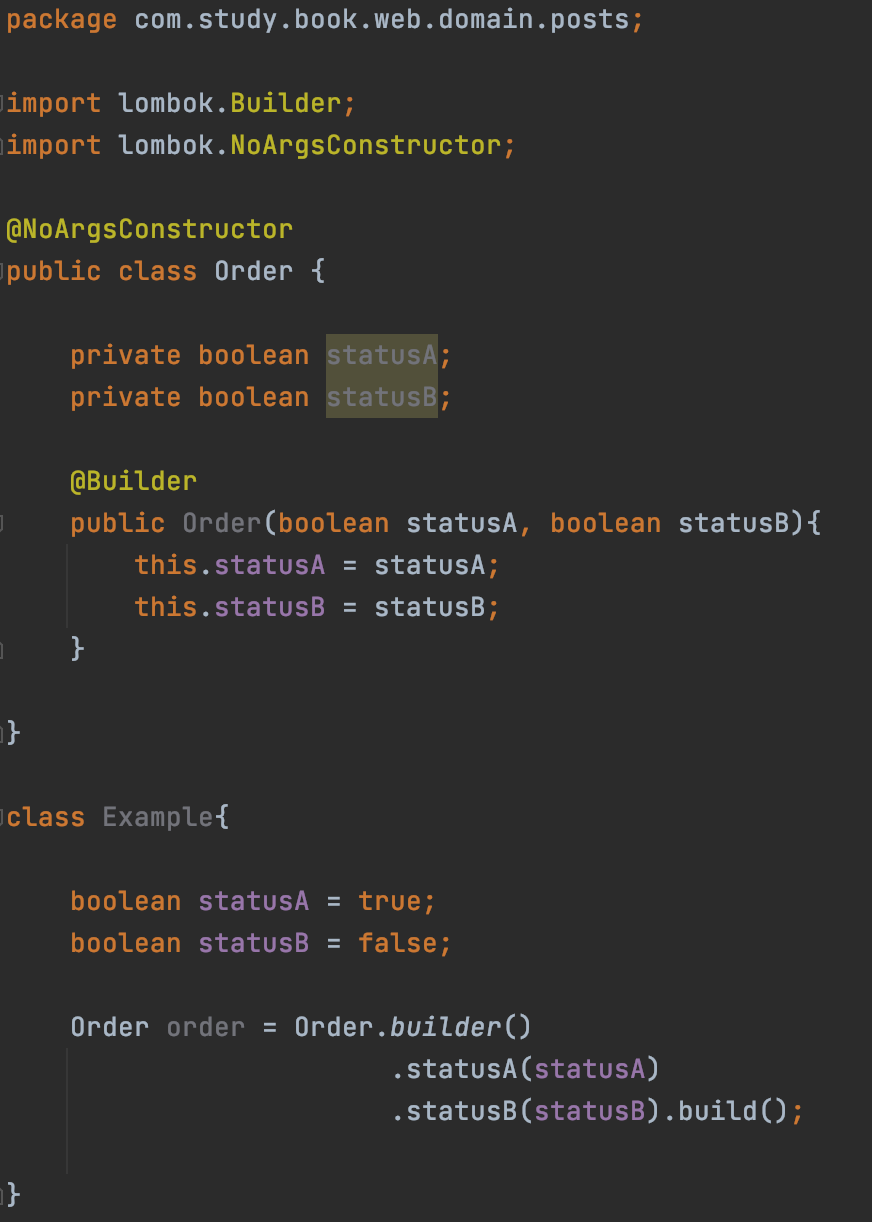
위와 같이 입력해야 하는 변수명이 setter 메소드로 생성되며 값을 할당할 수 있기 때문입니다. 빌더 패턴은 이러한 휴먼에러를 줄일 수 있는 유용한 패턴입니다.
'Development > Spring Framework' 카테고리의 다른 글
| [Spring Boot] API 생성하기 (0) | 2021.05.06 |
|---|---|
| 스프링 부트에서 JPA 사용하기 (3) (0) | 2021.05.06 |
| 스프링 부트에서 JPA 사용하기 (1) (0) | 2021.05.03 |
| 스프링 부트 롬복 추가하기 (0) | 2021.05.02 |
| 스프링 부트에서 테스트 코드 작성 (0) | 2021.05.02 |

